Cassandra Troy - Building Resilient Data Foundations
Have you ever thought about what makes the digital structures we rely on every single day truly stand the test of time? It's almost like the ancient tales of enduring cities, built to withstand a great many challenges. We often hear about systems that just keep going, no matter how much information gets thrown their way, or how many people want to look at it all at once. That kind of steadfast presence, a sort of digital bedrock, is what keeps our connected world moving along smoothly, you know?
When we talk about things that are truly dependable in the world of information, a name that often comes up is Cassandra. Now, not the prophetess from old stories, but a very real system that helps keep vast amounts of data in order. It's a type of database, open for anyone to use, and it handles information in a way that lets it spread out across many different places. This design means it can grow as much as you need it to, and it's always ready to go, which is pretty important for thousands of companies that count on it, actually.
This particular system, which we might think of as a modern-day "cassandra troy" for its strength and widespread use, provides a solid place for your information. It helps make sure that no matter how much data comes in, or how many people need to get to it, everything stays available and runs without a hitch. We're going to talk a bit more about what makes this system so trusted, how it manages to keep your data safe, and what it takes to get involved with it, so.
Table of Contents
- The Story of Cassandra Troy - A Digital Chronicle
- Why Do Companies Trust Cassandra Troy?
- How Does Cassandra Troy Keep Your Data Safe?
- Getting Started with Cassandra Troy - What You Need to Know?
- Contributing to the Cassandra Troy Narrative
- Where Can You Find Cassandra Troy's Instructions?
- Are There Specific Files for Cassandra Troy Setup?
The Story of Cassandra Troy - A Digital Chronicle
Every significant tool or system has a story, a kind of origin tale that explains its purpose and how it came to be. For our "cassandra troy," this powerful database, its story begins with a need for something different. Traditional ways of handling information just couldn't keep up with the huge amounts of data being created every second. So, a new kind of database emerged, one that didn't follow the old, structured rules, allowing for much more freedom and growth, you know.
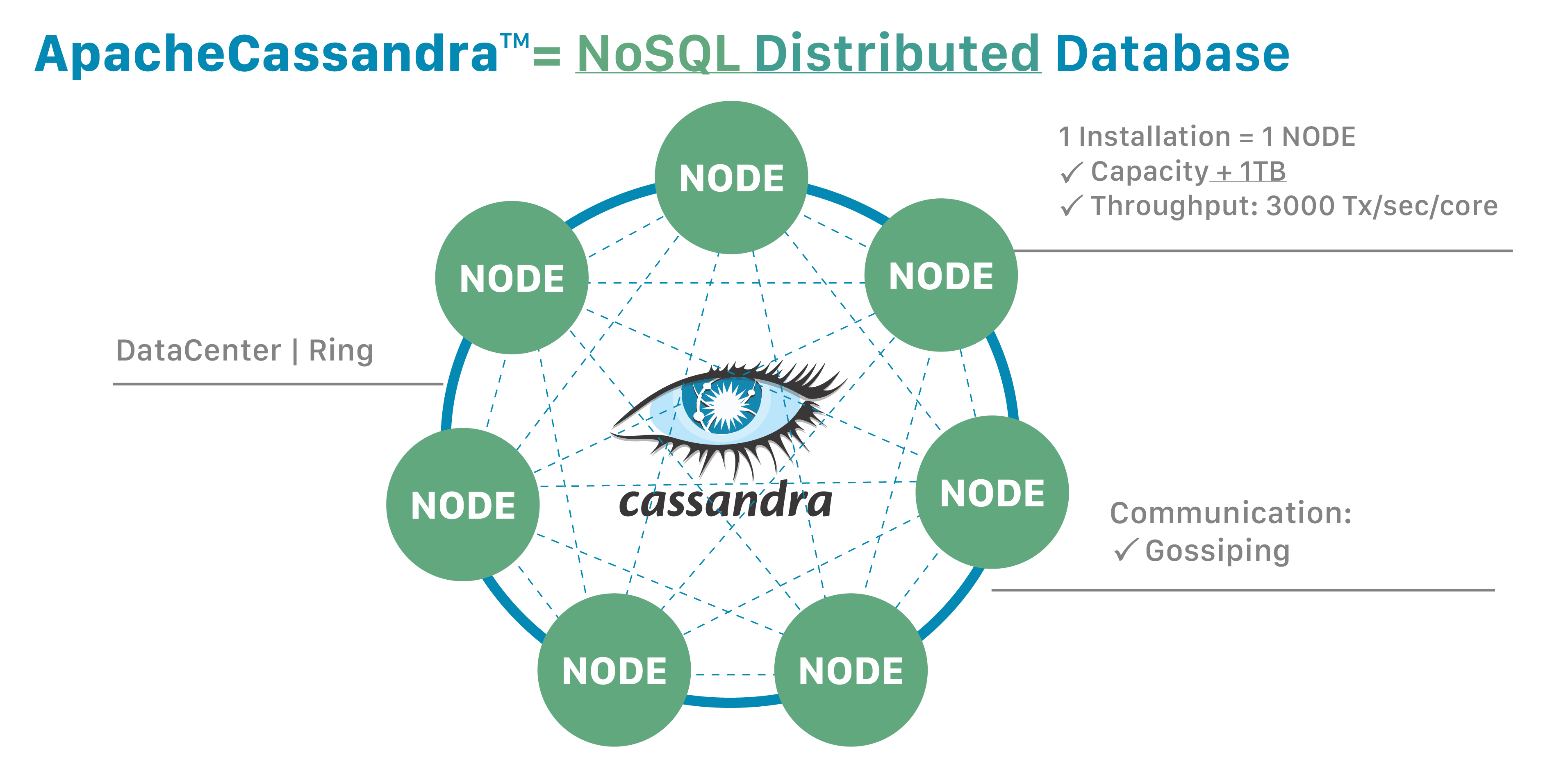
This particular database, Apache Cassandra, is what people call an open-source, NoSQL, distributed database. What that means, in simpler terms, is that anyone can use it and even help make it better, it doesn't stick to the very rigid tables you might be used to, and it spreads its work out across many different computers. This spreading out is a really big deal because it means the system can get much, much bigger without breaking a sweat, and it stays up and running even if some parts of it run into trouble. Companies that need to manage huge piles of information, and need that information to be ready whenever someone asks for it, often put their faith in this system, as a matter of fact.
It's a system that was built with the idea of being truly dependable, almost like a fortress for your data. When you have a lot of users, or a lot of things happening at once, you need a database that can handle all that activity without slowing down or, worse, stopping completely. Cassandra was designed with this kind of resilience at its very core, making it a favorite for places that absolutely cannot afford any downtime. It’s pretty impressive, actually, how it manages to keep everything flowing.
Key Characteristics of Cassandra Troy
Just like any important figure or structure, our digital "cassandra troy" has its own set of defining traits. These are the things that make it stand out and explain why it's chosen for so many critical tasks. We can look at these as its personal details, if you will, giving us a clearer picture of what it's all about. These characteristics help paint a picture of its capabilities and its overall purpose in the world of information management, in a way.
| Name of System | Apache Cassandra |
| Core Purpose | A system for managing very large amounts of data, spread across many machines, always ready for use. |
| Kind of Database | Open-source, NoSQL, Distributed |
| Main Strengths | Grows easily with your needs, stays available even if parts fail, handles lots of information at once. |
| Data Handling Method | Automatically makes copies of information in different places. |
| Community Involvement | Welcomes contributions from anyone who wants to help improve it. |
| What It's Used For | Trusted by thousands of businesses for keeping their important information safe and accessible. |
These traits really show why this system is so widely adopted. Its ability to spread information out and keep it copied means that even if one part of the system goes offline, your information is still there, ready to be used from another part. This kind of built-in toughness is what gives companies peace of mind when they're dealing with very important information, you know. It’s a very practical solution for keeping things running smoothly.
Why Do Companies Trust Cassandra Troy?
It’s a fair question to ask: what makes thousands of companies put their faith in a particular system like "cassandra troy"? The answer really comes down to a few key promises it makes and keeps. Businesses, especially those that operate on a very large scale, need certain assurances about their information systems. They need to know their data will be there, that it will handle growth, and that it won't suddenly disappear or become unreachable, basically.
One of the biggest reasons for this trust is its ability to grow without limits. Imagine a business that starts small but then suddenly has millions of customers. A traditional database might struggle to keep up, but Cassandra is built to just add more machines as needed, and it keeps working just as well. This means a company doesn't have to worry about outgrowing its data system, which is a huge relief for anyone planning for the future, you know. It's truly built for expansion.
Another very important point is its constant readiness. This system is designed so that your information is always there when you need it. It achieves this by making copies of your data and putting those copies in different places, sometimes even in entirely separate buildings. So, if one server or even an entire data center goes offline, the system just keeps on going, serving information from another copy. This constant availability is absolutely critical for online services, where every minute of downtime can mean lost business or unhappy customers, so. It’s pretty much always on duty.
The way it handles information also plays a big part in its trustworthiness. It's built to manage a lot of different types of information, and it does so in a way that lets you get to it quickly. This flexibility, combined with its ability to keep things running smoothly under heavy demand, makes it a very attractive choice for businesses that need a dependable backbone for their operations. It’s like having a team that never sleeps, always ready to fetch what you need, honestly.
How Does Cassandra Troy Keep Your Data Safe?
Keeping information safe and sound is, perhaps, one of the most important jobs any data system has. For "cassandra troy," this isn't just a feature; it's a fundamental part of how it operates. The core idea behind its safety measures is something called automatic replication. This means the system takes care of making copies of your information and spreading those copies around without you having to do anything extra, which is pretty convenient, you know.
When your application, say, a website or a mobile app, sends information to a Cassandra system, that information isn't just stored in one spot. For instance, if your application writes some data to a Cassandra node that's located on the U.S. West Coast, that data isn't just staying there. The system automatically makes copies of that data and sends it to other locations, perhaps to another data center on the East Coast, or even somewhere else entirely. This means you have multiple identical versions of your information in different physical places, as a matter of fact.
Why is this important? Well, imagine if the power went out at the U.S. West Coast data center, or if there was some kind of other issue. If your information was only stored there, it would be unreachable. But because "cassandra troy" has already made copies and placed them elsewhere, your application can simply get the information from one of the other locations. This way, your services stay up and running, and your customers don't even notice a problem. It's a bit like having multiple spare keys to your house, hidden in different places, just in case you lose one, you know.
This automatic copying and spreading of data is what gives Cassandra its remarkable ability to keep information available and protected, even when things go wrong. It's a very clever way to build resilience directly into the system, making it much less likely that you'll lose access to your important data. It provides a kind of peace of mind that's pretty valuable in today's connected world, honestly.
Getting Started with Cassandra Troy - What You Need to Know?
If you're thinking about using a system like "cassandra troy," it's natural to wonder how you actually get it up and running. There are some basic steps and tools that people use to connect their own applications to this database. For those who write programs using Java, for example, there are specific tools called Java drivers that help your application talk to Cassandra. These drivers are available in places like Maven Central, which is a common spot for developers to find software components, you know.
It's also worth noting that how you get the main Cassandra software itself has changed a bit over time for certain computer systems. For people using Debian or Red Hat operating systems, the places where you would normally find the software packages have moved. So, if you're setting things up on one of these systems, you'll need to be aware of these changes. It's not a big deal, just something to keep in mind when you're looking for the right files, as a matter of fact.
To really get a good feel for how "cassandra troy" works, especially at a high level, there are official resources available. These resources explain the main ideas behind Cassandra and give you a general picture of its operations. If you want to dig deeper and really get into the specifics, there are also more detailed instructions and explanations that go into all the finer points. It's a bit like learning the basic rules of a game first, and then later learning all the advanced strategies, you know. There's a path for every level of curiosity.
Contributing to the Cassandra Troy Narrative
One of the really cool things about "cassandra troy," or Apache Cassandra as it's formally known, is that it's an open-source project. This means that it's not owned by a single company; instead, a community of people from all over the world helps build it and make it better. This collaborative spirit means that anyone who wants to help improve the system is welcome to do so. It’s a very open and inviting environment, basically.
This openness extends to the information that explains how the system works. The instructions and explanations for Apache Cassandra are considered official, and they are also something that the community helps to create and maintain. If you read through them and you think of a way to make them clearer, or if you find something that could be added, you're actually encouraged to share your ideas. It's a bit like writing a shared story, where everyone can contribute a paragraph or a chapter, you know.
When someone wants to contribute to these instructions, they do it in a way that's pretty common in the world of open-source software. They put together their suggested changes, almost like a small piece of work, and then they submit it for others to review. This process ensures that any additions or changes are looked over by experienced people, making sure everything stays accurate and helpful. It’s a very organized way to keep things growing and improving, honestly.
So, if you ever find yourself working with "cassandra troy" and you have an idea for making its instructions better, or even for making the system itself better, you have a direct path to contribute. This kind of shared effort is what keeps open-source projects strong and current, benefiting everyone who uses them. It's a community effort that truly makes a difference, so.
Where Can You Find Cassandra Troy's Instructions?
When you're looking to understand how something works, especially something as important as a data system, having clear instructions is absolutely key. For "cassandra troy," there's a dedicated place where all the official guidance lives. This is the main spot to go if you want to learn about its main ideas, how it's put together, and what it does at a higher level, you know.
These instructions are set up to help you get a foundational understanding first. They go over the basic ideas and give you a general sense of how the system operates. It's a good starting point for anyone who is just getting to know Cassandra and wants to grasp its core principles without getting bogged down in too much detail right away. It helps you build a mental picture of the whole system, as a matter of fact.
However, if you're someone who wants to really get into the specifics and understand "cassandra troy" in a much more detailed way, there are also deeper sets of instructions available. These go into much more fine-grained explanations, helping you understand the inner workings and more advanced features. It’s a bit like having a basic map for a city, and then a very detailed street-by-street guide for when you need to explore every corner, you know. There’s guidance for every level of curiosity.
So, whether you're just dipping your toes in or you're ready to become a true expert, the official instructions are where you'll find everything you need. They are constantly being reviewed and updated by the community, ensuring they remain a very helpful resource for everyone who uses or works with this powerful system, honestly.
Are There Specific Files for Cassandra Troy Setup?
When you're getting ready to set up "cassandra troy" on a computer system, especially if you're using certain kinds of operating systems like Debian or Red Hat, there are some particular files you need to be aware of. These files tell your computer where to find the software packages it needs to install Cassandra. It's a bit like telling your computer where to look for the right ingredients to build something, you know.
For Debian systems, there's a file typically called `sources.list`. This file contains a list of places where your computer can download software. And for Red Hat systems, there's a file called `cassandra.repo`. This file serves a similar purpose, pointing to the locations of Cassandra software. These files are pretty important because they ensure your system knows exactly where to get the official and correct versions of the software, as a matter of fact.
It’s important to make sure these files are set up correctly on your system. If they're not, your computer might not be able to find the Cassandra software, or it might try to get it from the wrong place. So, when you're going through the setup process, checking these specific files is a step you won't want to miss. They are essentially the directions your computer follows to bring "cassandra troy" to life on your machine, so.
Ensuring these setup files are properly configured is a small but very important part of getting Cassandra running smoothly. It helps everything connect as it should, making the rest of the installation process much easier. It's a little detail that makes a big difference in the overall experience, honestly.
This discussion has covered how Apache Cassandra, our "cassandra troy," stands as a very dependable system for handling large amounts of information. We've talked about its open-source nature, its ability to grow with your needs, and its built-in ways of keeping your data safe by making copies in different places. We also touched upon how people can get started with it, find its instructions, and even contribute to its ongoing development, which is pretty neat. This system truly offers a solid foundation for any data-heavy operation, providing peace of mind through its constant readiness and ability to handle vast amounts of activity.
Apache Cassandra | Apache Cassandra Documentation
Por qué Cassandra no es una base de datos cualquiera.

Cassandra
